
IBM Spectrum Protect - przesyłanie danych z wykorzystaniem protokołu S3
20.11.2020 IBM opublikował nową wersją oprogramowania IBM Spectrum Protect – 8.1.11.
Jedną z większych nowości jest możliwość stworzenia portalu, który umożliwia przesyłanie danych do i z serwera z wykorzystaniem protokołu S3. Funkcjonalność ta pojawiła się już we wcześniejszych wersjach ISP natomiast była ograniczona tylko i wyłącznie do składowania danych pochodzących z IBM Spectrum Protect PLUS. Dlaczego ta funkcja jest tak ważna i co nowego wnosi? O tym przeczytacie poniżej.
Procedura wdrożenia IBM Spectrum Protect
Zacznijmy od początku. Instalacja. Nie będziemy w tym artykule omawiali procesu instalacji serwera ISP. Skupimy się tylko i wyłącznie na protokole S3. Warto podkreślić, że dane przesyłane z wykorzystaniem tego łącza możemy składować na puli typu container, zatem trzeba ją najpierw stworzyć:

def stg container stgt=directory
oraz zapewnić jej przestrzeń:

def stgpooldir container /tsm/cont/c01
Gdy już mamy zapewnione miejsce składowania danych należy stworzyć instancję ObjectAgenta oraz politykę, według której zasad będziemy składowali dane. Możemy to zrobić całkowicie manualnie lub wykorzystać gotowe polecenie „define objectdomain”. Parametr STANDARDPOOL wskazuje pulę składowania danych. Do wywołania polecenia możemy dodać parametr COLDPOOL=STG_NAME. Jaka jest różnica:
- STANDARDPOOL – pula przeznaczona dla danych klientów obiektowych
- COLPOOL – pula przeznaczona na dane pochodzące z systemu SPECTRUM PROTECT PLUS
W momencie powoływania nowego klienta, może on przyjąć 2 typy, które determinują miejsce składowania danych. O tym w dalszej części wpisu.

def objectdomain s3dom standardpool=container
Zobaczmy, co system dla nas stworzył:
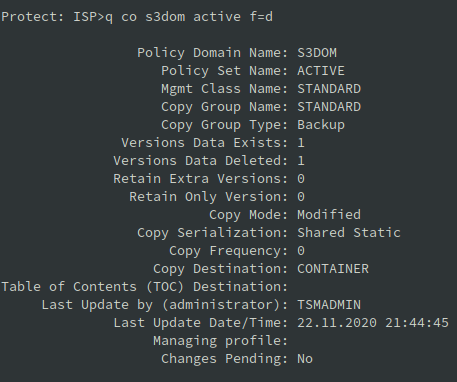
Powyżej widzimy całą dobrze znaną strukturę. Jest wskazana pula CONTAINER, jako miejsce docelowe. Co ciekawe i ważne, zwróćmy uwagę na wartości parametrów VERE, VERD, RETE, RETO. Widzimy, że przechowujemy tylko jedną, aktywną wersję pliku. Każda kolejna wersja, jeśli taka powstanie, staje się wersją nieaktywną i będzie usuwana w procesie EXPIRE INVENTORY. Z poziomu klienta S3 nie mamy również dostępu do innych niż najnowsza wersji pliku, zatem ustawienie polityki w ten sposób jest jak najbardziej logiczne.
Pamiętajcie, w momencie składowania danych, jeśli chcecie zapewnić wersjonowanie danych, musicie najlepiej dodać unikalny identyfikator w nazwie przesyłanego pliku, timestamp lub cokolwiek innego, co pozwoli jednoznacznie określić plik. Nadgranie pliku o tej samej nazwie spowoduje jego bezpowrotne utracenie.
W tym momencie mamy przygotowaną podstawową strukturę potrzebną do przyjmowania danych. Pozostało jeszcze stworzyć ObjectAgenta oraz definicję ObjectClienta. Więc po kolei.
ObjectAgent. Tutaj też IBM przyszedł z pomocą i dostajemy gotową komendę:

def server s3agent hladdress=isp lladdress=9000 objectagent=yes
Wykonanie tej komendy tworzy nam wszystkie niezbędne certyfikaty i umieszcza je w lokalizacji:
/katalog_instancji_isp/S3AGENT
Ważne, że na jednej instancji serwera ISP możemy uruchomić jedną instancję ObjectAgenta.
Po wykonaniu komendy w konsoli serwera ISP należy wykonać jedno polecenie z poziomu konsoli systemu operacyjnego:

„/opt/tivoli/tsm/server/bin/spObjectAgent” service install
„/tsm/tsminst1/S3AGENT/spObjectAgent_S3AGENT_1500.config”
Szybka weryfikacja:
netstat -plnv | grep 9000


Z powyższego wywołania widzimy, że agent został uruchomiony i nasłuchuje na porcie 9000.
W katalogu S3AGENT powstały następujące pliki:

Znajdziemy tutaj protect.log, z którego odczytamy co aktualnie dzieje się w komunikacji pomiędzy klientem, a agentem S3. Jest tutaj również konfiguracja ObjectAgenta oraz zestaw plików certyfikatów. Plik agentcert.crt skopiujemy na klienta aby wykorzystać go w ustanowieniu bezpiecznej komunikacji.
Czas na stworzenie ObjectClienta:

reg node s3client domain=s3dom type=objectclient replstate=enabled
W informacji zwrotnej otrzymaliśmy zestaw ACCES_KEY_ID oraz SECRET_ACCESS_KEY. Należy te informacje zachować gdyż będą nam potrzebne w procesie konfiguracji klienta. Jeśli je utracimy lub zostaną skompromitowane, to z wykorzystaniem OperationsCenter można wygenerować nową parę.
Zwróćmy uwagę na parametry, jakie otrzymał nowo stworzony node:

Rola jako ObjectClient – other. W przypadku integracji z Spectrum Protect Plus ten parametr byłby ustawiony inaczej. Zostanie to omówione w kolejnym wpisie. Na tej podstawie system decyduje, może nie bezpośrednio, czy dane trafiają do STANDARDPOOL lub COLDPOOL.
Czas na instalację czegoś, co pozwoli nam się komunikować z wykorzystaniem protokołu S3 z naszego klienta. My zdecydowaliśmy się na narzędzia dostarczane przez AWS w postaci awc-cli. Natomiast jest dostępne dużo innych narzędzi, z których możecie skorzystać. W późniejszej fazie testów pokażemy, że dostęp do tych samych danych można uzyskiwać z różnych platform i narzędzi.
Po zainstalowaniu aws-cli dokonujemy wstępnej konfiguracji:


Pobieramy z serwera ISP plik certyfikatu:

Oraz weryfikacja, ze strony klienta S3:


I ze strony serwera ISP:

Nie pozostaje nic innego niż wgrać dane. Przygotowaliśmy 3 pliki, 1MB, 10MB, 100MB. Każdy z nich zostanie przekazany z wykorzystaniem protokołu S3. Zacznijmy od pliku 1MB:

Wgraliśmy plik o wielkości 1MB do bucketu test. Zobaczmy czy faktycznie się on tam znajduje:


Oraz sprawdźmy ze strony serwera ISP:
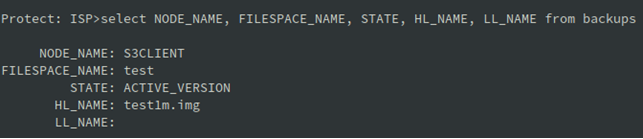
By być w 100% pewnym pobieramy plik z serwera ISP i obliczę sumę kontrolną jego i oryginału:


Wszystko jest w jak najlepszym porządku. Odtworzyliśmy dokładnie to samo, co zbackupowaliśmy.
Zróbmy test na większym pliku, 10MB.

I przeprowadźmy weryfikację po stronie serwera ISP:
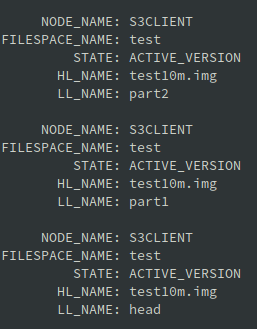
Tutaj zachowanie jest nieco inne. Jeden plik, ale nieco większy został podzielony na mniejsze części i jest w ten sposób przechowywany. Obiekt z nazwie HEAD zawiera w sobie informacje o poszczególnych częściach niezbędnych do przywrócenia całości obiektu. Niewątpliwą zaletą jest fakt, że większe obiekty przesyłamy większą ilością sesji przez co maksymalnie wykorzystujemy dostępne pasmo (btw – możemy je oczywiście ograniczyć).
Wgrajmy plik 100MB:


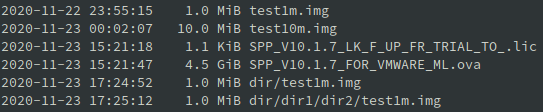
Widzimy, że plik 100MB składa się na serwerze ISP z 14 części (1 head + 13 części z danymi).
Możemy robić podkatalogi w ramach bucketu:

Czy do tak zgromadzonych danych można dostać się z innego systemu? Tak. I to jest niezaprzeczalna zaleta tego rozwiązania. Możemy bez najmniejszego problemu przesyłać dane pomiędzy różnymi platformami sprzętowymi i systemowymi. Jedynym warunkiem jest możliwość instalacji klienta S3 i uzyskanie poświadczeń.
Logowanie za pomocą WinSCP
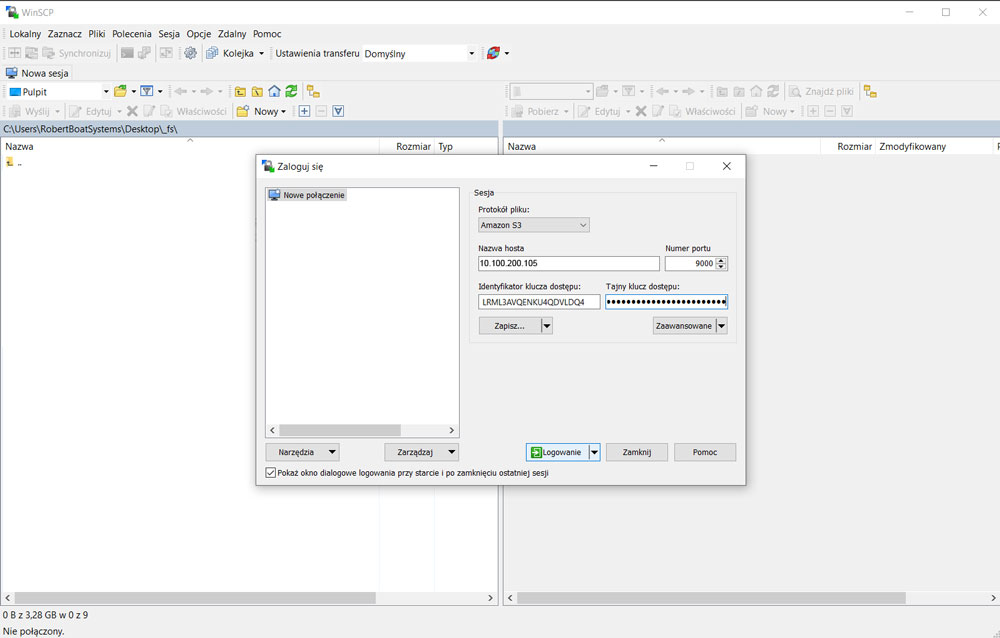
Należy pamiętać, aby w Zaawansowanych Ustawieniach WinSCP, w sekcji „Środowisko/S3” zmienić „Styl adresu URL” na „Ścieżka”.
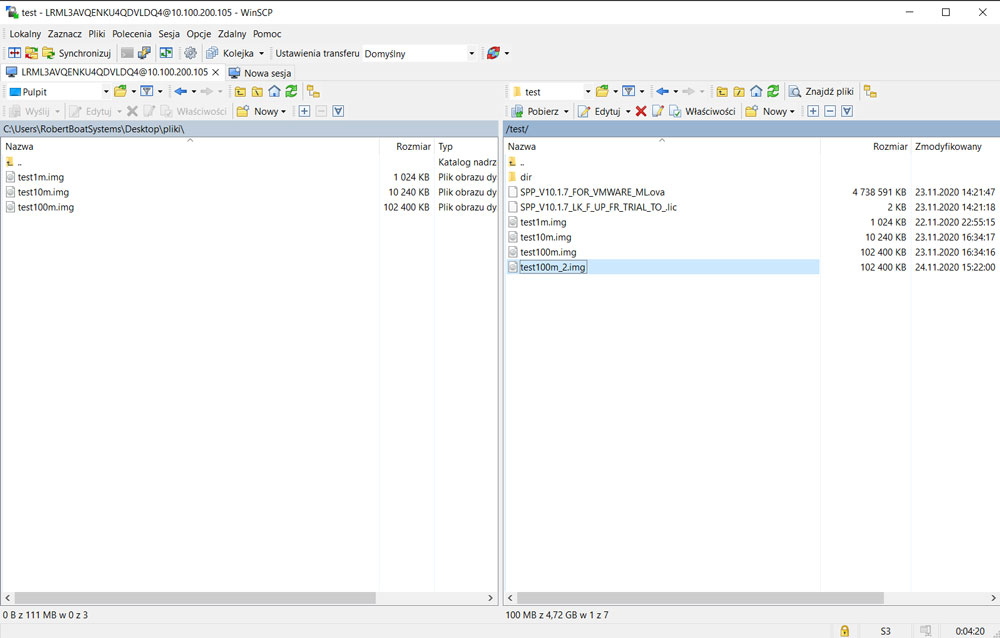
Kopiujemy 100mb plik na komputer lokalny.
Wysyłamy 100mb plik do lokalizacji docelowej.
100mb plik został pomyslnie wysłany.
A kiedy już nie chcemy przechowywać jakiegoś pliku?





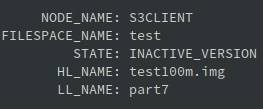
Oczywiście dane z serwera ISP nie znikną natychmiast. Zostały oznaczone jako nieaktywne i zostaną usunięte podczas najbliższego procesu expire inventory:
Do czego obsługa protokołu S3 przez serwer ISP może nam się przydać w praktyce?
Nasuwa się kilka mniej lub bardziej oczywistych rozwiązań:
- backup systemów i aplikacji, które oficjalnie nie są spierane przez IBM Spectrum Protect
- wymiana plików pomiędzy użytkownikami
- przenoszenie obiektów pomiędzy różnymi platformami sprzętowymi i systemowymi
Dodatkowo warto pamiętać, że dane wgrane do serwera IBM SP za pomocą protokołu S3 podlegają takim samym zasadom jak wszystkie inne dane. Zatem można je replikować i odtwarzać na innym serwerze, są deduplikowane i kompresowane a opcjonalnie mogą być również szyfrowane. Na ten moment nie jest wspierane przenoszenie danych na taśmy i na inne poziomy wolniejszego storage’u.
Autor: Przemysław Jagoda
